

AWS Dynamodb
DynamoDB is a NOSQL AWS database that is a highly available, distributed database with replication across multiple AZs.
This DB can be scaled to 100 TB storage capacity, trillions of records. The transaction speed is fast and consistent in a performance like millions of records per second, the low latency, especially during retrieval. It can be configured to dynamic scaling using the auto-scaling feature. The DB integrated with IAM and AWS authorization and administrative controls. It has an event-driven programming feature with DynamoDB Stream.
DynamoDB Overview
DynamoDB consists of Tables. And each table consists of rows and attributes. The table has a primary key that needs to be defined during table creation time. An infinite number of items(row) can be inserted in each table. Items have attributes, and each value is mapped to attributes. It allows nested attributes, or each attribute can represent a single column. The attribute can be added after the creation of the table without any impact on existing data. The maximum size of an item(row) is 400 KB.
Data types supported
- Scalar types – String, Number, Binary, Boolean, Null
- Document types – List and map.
- Set types – String Set, Number Set, Binary Set
Partition
DynamoDB’s inbuilt Hashing algorithm is responsible for hashing the Primary Key while writing the data and storing the data in different partitions. Partition is the process of splitting a big chunk of data into small-size data and evenly distributing the data in multiple locations (nodes, hard disk, etc.).
Primary Key
There are two options to create a primary key – “Partition Key” and “Partition Key and Sort Key”.
Partition Key
The Partition Key option is also called a Hash key. The partition key must be unique for each item. We create the hash key to make the key more diverse and distribute the data.
Example: Employee Table where EmployeeId is a Primary Key and Firstname and Lastname are attributes.
| EmpId | FirstName | LastName |
|---|---|---|
| De4G^&fd@ | John | Peter |
Partition Key And Sort Key
The “Partition Key and Sort Key” option is also called Hash+Range. Again, the combination of Hash value and range must be unique for each item. Here the data will be grouped by partition key.
Example – EmpId is the primary key in the below table, and DeptId is the sort key. So, EmpId will group the data, and (EmpId+DeptId) will be unique for each row.
| EmpId | DeptId | EmpName | Salary | DeptName |
|---|---|---|---|---|
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| 343F454&*2 | 4354 | Jimmy | 2000 | Marketing |
RCU
Read Capacity Units or RCU is throughput for reads.
Eventually Consistent Read
Eventually Consistent Read is a default read mode. While reading, there is no guarantee the client will receive the latest data from DynamoDB, and DynamoDB may return stale data. Stale read could happen if the latest data is not replicated to all nodes. But eventually, after a few milliseconds, all nodes will have the latest data.
In the case of Eventually Consistent Read, one RCU means reading two rows of size up to 4 KB.
For example :
- 2 rows and the size of each row is is 4 KB – This is equivalent to 1 WCU
- 2 rows and the size of each row is 4.5 KB – this is equivalent to 2 WCU.
Strongly Consistent Read
In this read mode, there is a guarantee that DynamoDB will replicate the latest to all nodes and always return correct data to the client. “ConsistentRead” parameters must be set to enable Strong Consistent Read. It consumes twice RCU than Eventually Consistent Read.
In the case of Strongly Consistent Read, one RCU means reading one row of size up to 4 KB.
For example :
- 2 rows and the size of each row is is 4 KB – This is equivalent to 2 WCU.
- 2 rows and the size of each row is 4.5 KB – this is equivalent to 4 WCU.
WCU
WCU – Write Capacity Units is a throughput for writes. 1 WCU means, writing one row per second of the size up to 1 KB.
For example :
- 2 rows and size of the each row is 1 KB – This is equivalent to 2 WCU
- 1 row and of the row is 1.5 KB – this is equivalent to 2 WCU.
DynamoDB read and write capacity mode
Provisioned Mode
Provisioned mode is the default mode. You plan beforehand and specify the read/writes per second capacity. In this mode, you provision reads and writes capacity unit, i.e., you have to pay a fixed amount for provisioned reads and writes capacity unit.
On-Demand Mode
On-Demand mode is a dynamic mode i.e. reads and writes capacity unit does not need to be planned beforehand. The capacity of the cluster will dynamically increase/decrease based on the workload. The cost will be calculated based on the actual use of reads and writes capacity units. The price per unit is more expensive compared to Provisioned mode.
That concludes that provisioned mode should be selected for the predictable workload to save the running cost of the project. Start with On-Demand mode and switch to Provisioned mode after determining the application traffic load.
Throttling
Throttling can happen if the traffic is more than the capacity of DynamoDB. The auto-scaling option can be enabled to handle the throughput RCU, or WCU demands more than provisioned RCU and WCU. If the Auto Scaling option is enabled, then DynamoDB will automatically handle extra throughput demand more than provisioned and up to “Burst Capacity”. Beyond “Burst Capacity” the system will throw the exception “ProvisionedThroughputExceededException”.
Reason for Throttling –
Hot Key – When a specific partition key is accessed many times.
Hot Partition – When a large volume of data is accessed from a single specific partition.
Large Items – When large-size items are being accessed repeatedly.
Data throttling can only happen in the case of provisioned mode and not for on-demand mode.
DynamoDB API
GetItem
API to read the data from DynamoDB using the primary key – Hash or Hash+Range. ProjectionExpression is used to retrieve a few specific attributes.
Query
The is to retrieve the data from DynamoDB tables and Indexes using KeyConditionExpression. Rules for KeyConditionExpression –
- Must use equal (=) condition with Primary Key.
- A conditional operator with a Sort key is optional. Few valid operator – =, <, <=, >=
FilterExpression
FilterExpression is to filter the data on the server side after querying the data. This can be applied to non-key attributes, i.e., other than HASH and HASH+Range.
The Pagination needs to be implemented if more than the maximum limit (1 MB).
Scan
Scan returns the entire table then the filter can be applied on the client side. “Scan” is inefficient compared to GetItem. Extra RCU will be used to retrieve unnecessary data. To reduce the impact use “Limit”. ProjectionExpression and FilterExpression are valid operations in Scan but will not reduce the RCU.
Multiple workers can be engaged to retrieve the data faster, known as Parallel Scan.
The Pagination must be implemented if the retrieved data size exceeds the maximum (1 MB) limit.
PutItem
PutItem is to insert a new record(Item) if the given Primary key does not exist; otherwise, this will fully replace the item with a matching primary key.
UpdateItem
UpdateItem is to insert a new record(Item) if the given Primary key does not exist; otherwise, this will update the existing item attributes of that matching primary key item.
ConditionWrite
Update the Item (record) if condition satisfied.
DeleteItem
DeleteItem is to delete an item using either condition or without condition.
DeleteTable
Delete the table along with all data items.
BatchOperation
BatchOperation is always advisable to plan and execute the batch operation to read/write multiple data together instead of calling read/write operation for individual items. BatchOperation reduces the latency (delay between request and response) by reducing the number of API calls. It runs in parallel and saves transaction time.
BatchGetItem
BatchGetItem retrieves multiple items from one or multiple tables using a parallel mechanism. This allows to read a total of 16 MB of data and a maximum of 100 items per batch. UnprocesseKeys will be returned if any key is not processed because of capacity.
BatchWriteItem
Maximum 25 PutItem and/ DeleteItem per call. It doesn’t allow to update the item. BatchWriteItem allows to write a total of 16 MB data and 400 KB data per item. In case the system can’t write the processed portion of the data, then those will be returned as part of UnprocessedItems.
PartiQL
PartiQL is an SQL-like command to manipulate DynamoDB tables. Using PartiQL, the records can be inserted/updated/deleted from the DynamoDB tables. It also supports batch operation to update multiple records altogether.
Example :
- SELECT * FROM ‘Employee’
- SELECT * FROM ‘Employee’ WHERE ‘EmpId’ = ‘< partition Key Value >’ and DeptId = ‘<Sort Key Value >’
- UPDATE ‘Employee’ SET ‘< attribute name >’ = ‘< attribute value >’ WHERE ‘EmpId’ = ‘< partition Key Value >’ and DeptId = ‘< Sort Key Value >’
- DELETE FROM ‘Employee’ WHERE ‘EmpId’ = ‘< partition Key Value >’ and DeptId = ‘< Sort Key Value >’
DynamoDB Secondary Index
Suppose there is an application functional necessity to retrieve the data from DynamoDB based not only on the Primary key but also other attributes. These kinds of data retrieval patterns can be achieved using the secondary Index.
DynamoDB supports two kinds of Index – Local Secondary Index and Global Secondary Index.
LSI
The local Secondary Index (LSI) is an additional sort key for the DynamoDB table. This uses the same Primary Key of the base table and includes any other columns of type String, number, or Binary as an additional sort key.
For example, you could create a LSI on Salary count to find all employees in a given salary range.
| EmpId | DeptId | EmpName | Salary | DeptName |
|---|---|---|---|---|
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| 343F454&*2 | 4354 | Jimmy | 2000 | Marketing |
LSI needs to be built during table creation.
GSI
Unlike LSI, the Global Secondary Index (GSI) can be added/modified after table creation. GSI is an alternate Primary key that can be used to read the data from the table without the base primary key. RCU and WCU must be provisioned on GSI because this new set of primary keys will be maintained at the DynamoDB cluster. GSI can be created on attribute type – String, Number, or Binary). The choice of GSI attribute is crucial in terms of throttling. The main table will be throttled if throttling (error due to the active transaction being more than capacity) happens on GSI.
Base Table
| EmpId | DeptId | EmpName | Salary | DeptName |
|---|---|---|---|---|
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| De4G^&fd@ | 3436 | John | 1000 | Sale |
| 343F454&*2 | 4354 | Jimmy | 2000 | Marketing |
GSI created to read the data based on Department ID and Location ID
| EmpId | DeptId | LocCode | EmpName | Salary | DeptName |
|---|---|---|---|---|---|
| De4G^&fd@ | 3436 | 1 | John | 1000 | Sale |
| De4G^&fd@ | 3436 | 3 | John | 1000 | Sale |
| 343F454&*2 | 4354 | 2 | Jimmy | 2000 | Marketing |
DynamoDB TTL
DynamoDB TTL (Time To Live) executes the auto process to delete the records after an expiry timestamp. The Unix epoch timestamp format is used to populate each record’s TTL attribute/column. The TTL process doesn’t consume any WCUs, i.e. there will not be extra cost.
DynmoDB executes the first background process to check each table’s TTL value and marks the expiry record. Then, it performs another background process to delete the marked records physically. It may take up to 48 to complete the whole process of marking and deleting the records. After deleting the items, DynamoDB also deletes the items from both LSIs and GSIs. The deleted items are also populated in DynamoDB streams.
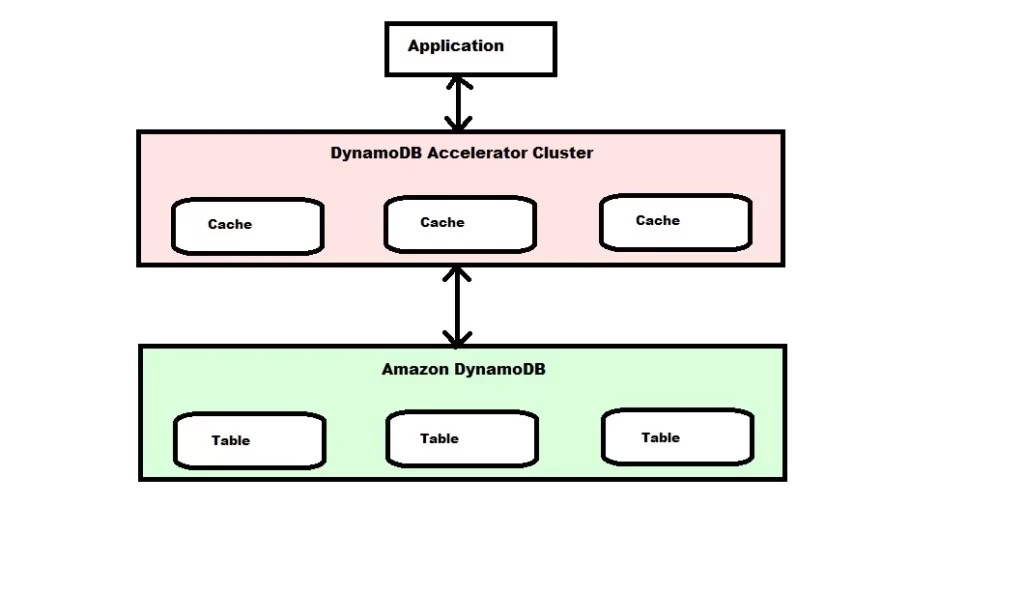
DynamoDB Accelerator (DAX)
DAX is an in-memory cache system to cache necessary data so the response time can be improved to microseconds for repeatable reads and queries. It resolves the HOT key problem. HOT Key issue may arise if you read the same key too many times within a short range of time, then you may get throttled on your RCUs. DAX is fully managed by AWS and highly available using multiple nodes in a DAX cluster. There could be a maximum of 10 DAX nodes in a cluster, and the recommendation is to have at least three nodes per cluster in a multi-AZ setup. It uses encryption at rest for security reasons.
Architecture :
Conclusion
DynamoDB is helpful for an application to store a massive volume of data, like a log ingestion system, metadata storage, chatting system, sensor application, machine learning system, etc.
DynamoDB is a NoSQL database, so it may not be suitable for all use cases. For example, it should not be used as traditional RDBMS uses RDS instead. It is not ideal for complex transactional systems, or there is a necessity to write complex joins.
DynamoDB is not suitable for storing large binary objects (BLOB). Keep the BLOB object in AWS S3 and store the metadata and references of the BLOB object in DynamoDB. It is suitable to store hot data in DynamoDB and colder in S3.
Manage inventory efficiently using AlnicoSoft.